(Giải thích các khái niệm về AI cho người mới làm quen)
Ngày hôm nay, giới AI lại ồn ào chào đón việc Google ra mắt mô hình ngôn ngữ lớn Gemma của hãng. Gemma được xem là “open model” như Demis Hassabis, Co Founder DeepMind-Google thông báo (hình dưới).
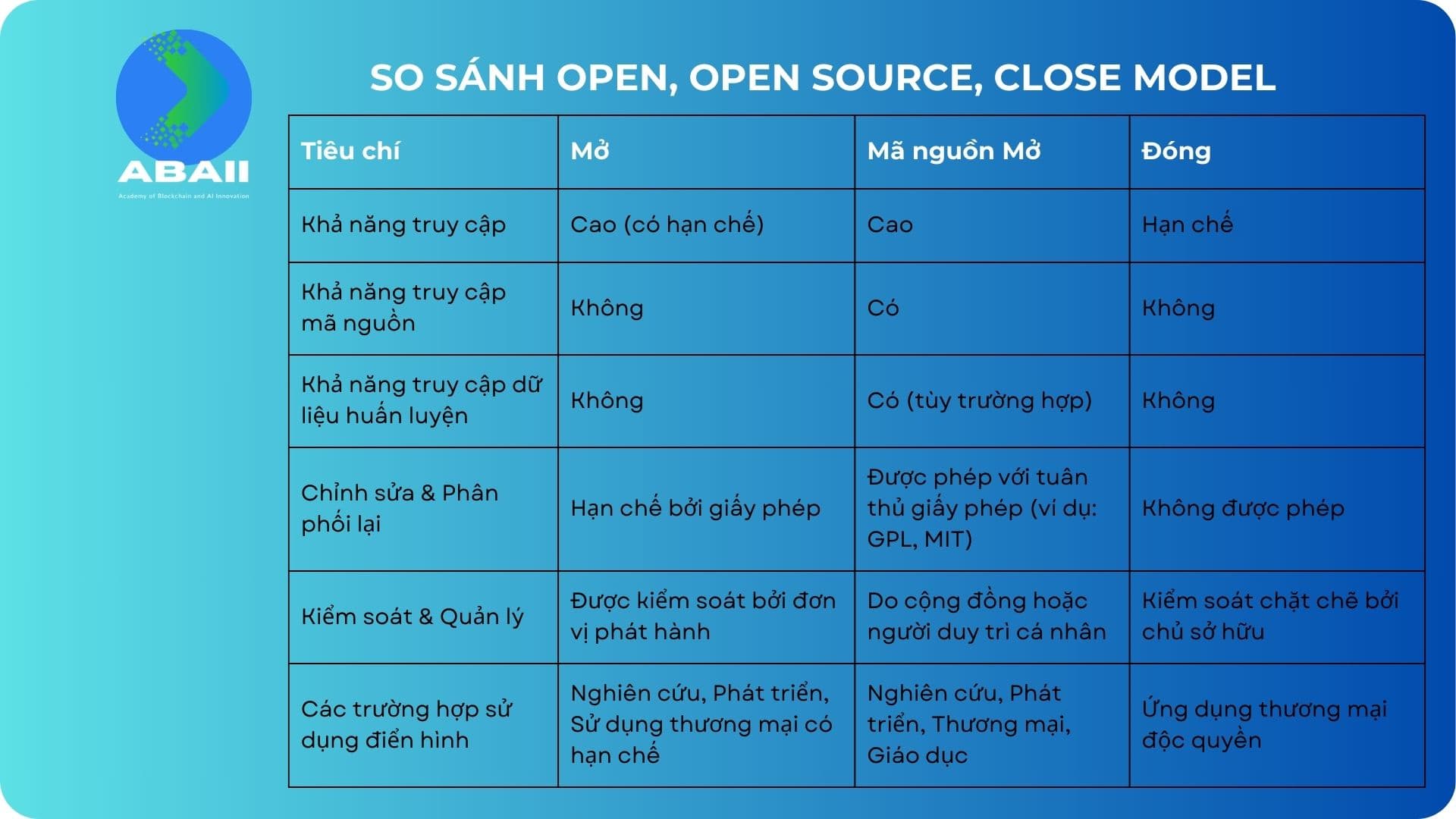
Trong thế giới của các mô hình ngôn ngữ lớn (LLM), thuật ngữ “open” và “open source” thường gây nhầm lẫn. Dù có vẻ giống nhau, nhưng thực tế, chúng mang ý nghĩa khá khác biệt. “Open” thường ám chỉ việc một mô hình được công bố rộng rãi, cho phép cộng đồng sử dụng và áp dụng nó trong nghiên cứu hoặc ứng dụng thực tế. Tuy nhiên, điều này không nhất thiết có nghĩa là mã nguồn (source code) hoặc dữ liệu huấn luyện (training data) của mô hình được chia sẻ công khai.
Trái lại, “open source” đề cập đến việc toàn bộ mã nguồn, bao gồm cả dữ liệu huấn luyện và mã để tạo ra mô hình, được công bố một cách minh bạch. Điều này cho phép cộng đồng không chỉ sử dụng mô hình mà còn có khả năng điều chỉnh, cải thiện và thậm chí tái huấn luyện mô hình dựa trên nhu cầu cụ thể của họ.
Một ví dụ điển hình là Llama 2 của Meta, được mô tả là “open” với việc cung cấp trọng số (weights) mô hình cho công chúng. Tuy nhiên, Meta không chia sẻ toàn bộ mã nguồn hoặc quy trình huấn luyện chi tiết, làm cho Llama 2 không hoàn toàn là “open source”. Cách tiếp cận này giúp Meta giữ được quyền kiểm soát đối với việc phát triển và ứng dụng của mô hình, đồng thời vẫn khuyến khích sự đóng góp và sử dụng rộng rãi trong cộng đồng AI.
Tương tự như vậy với mô hình Gemma của Google. Những mô hình “mở” (“open”) trên chỉ cung cấp “weights” (trọng số) hay “parameters” (tham số) mà bạn có thể tải về máy rồi chạy (dùng llama.cpp, lmstudio, ollama,… để chạy) hay như người ta nói đó là các “open weights model” dù thuật ngữ này không được chấp nhận rộng rãi trong giới.
Sự khác biệt giữa “open” và “open source” trong LLM không chỉ ảnh hưởng đến quyền truy cập và sửa đổi mô hình mà còn liên quan đến trách nhiệm và cách thức mà các mô hình này được triển khai và sử dụng trong thực tế. Khi chia sẻ về LLM, quan trọng là phải rõ ràng về mức độ “mở” của mô hình để cộng đồng có thể hiểu và áp dụng chúng một cách phù hợp. (xem hình)
Các mô hình như GPT-4, Gemini, Claude, Mixtral 8x7b (Next), Grok, Pi đều là mô hình đóng “Close Model”.
- bài viết trên facebook